
Alex Danilychev leads development for Magic Eden's Solana platform core features - including indexing, protocol, and product features.
As the leading cross-chain NFT platform for Solana, Ethereum, and Polygon, Magic Eden handles a significant amount of traffic daily, both through our core website as well as our API that we expose to the community. In 2021, Magic Eden processed over 1.5x more transactions than OpenSea, with each tx reflecting on the site in under 1 second.
While our user base scaled, our stack struggled to keep up. Early 2022 was a mix of frequent outages, slow load times, and many a stale NFT listing. While the original backend got the job done, we realized that we couldn't achieve the stability and performance our users needed without a rewrite.
After rebuilding our indexing and backend systems last year, we were proud to deliver a fast and much more reliable backend, including the following highlights:
10x faster wallet and collections page loads
10x faster e2e latency (duration from a user seeing a transaction succeed to when our site reflects this information)
Significant cost savings
Wins
Our Wallet page saw one of the biggest speedups getting over 10x faster

Overall p99 of our API across all endpoints improved dramatically, tying up fewer server resources

The time for our internal systems to reflect the most recent state of Solana improved 30x, usually below 1s end-to-end

Recently, we’ve hit up to 4000 queries per second across all of our APIs. Our APIs for fetching NFTs for specific collections hit 100qps and 500qps at peak. Our system handles 300 transactions a second at peak, with transactions reflecting on the site from the blockchain within seconds.
We’ll go into the details of the architecture behind these improvements in subsequent posts, but let’s set the table on Solana development.
Web3 Development
How Web3 development differs from traditional web development
There are plenty of in-depth descriptions of the difference between a traditional web app and a dApp (an application built on top of the blockchain). Some of my favorites include Web2 vs Web3 by Drift, Web2 vs Web3 by the Ethereum Org, and Architecture of a Web3 App.
For now, we’ll focus on the largest difference: the application data source.
In a traditional web application, the core data for the application will be stored in a database managed by the application developer. The application developer has full control over the data modeling, table schemas, and workloads. The application developer can decide the choice of database, and optimizations like indexing, normalization, and caching based on the workloads they expect their app to take. All applications reads and writes pass through the same stack and database.
In web3 - that core data is stored in a decentralized, globally available, permissionless database called a blockchain. All application writes that are initiated by the user go to the blockchain, not the developer’s database. The developer can deploy new programs to that blockchain, but the fundamental properties of being distributed and general-purpose can bog down a vanilla web app without additional optimization.
To recap:

Reads | Writes | |
WebApp | App Database | App Database |
dApp (no backend) | Blockchain RPC Provider | Blockchain RPC Provider |
dApp (custom backend) | App Server | Blockchain RPC Provider |
Example Web3 dApp
Let’s say you want to build a dApp that allows users to stake Solana with your program.
This will involve setting up your frontend - typical HTML, CSS, Javascript, potentially with a frontend framework like React. You’d then write your smart contract (Anchor is popular) and then deploy it to the chain. The final step is to integrate your app to write and read from the Solana blockchain via web3js, and deploy!
At this point, you’ve managed to build your dApp, get it deployed, and start serving users! You didn’t even need to deploy a backend server. RPC providers, backed by the blockchain, handle your read/write traffic and get you functional quickly.
Things are going well, but as you scale your user base, you hit a wall with performance. It becomes challenging to add new analytical features like a leaderboard for most prolific stakers. You check the network log and notice that getProgramAccounts takes an incredibly long time to fetch the token accounts relevant to the users on your site!
Solana Storage Model
Solana is a write-optimized chain, meaning it is designed to prioritize the speed and efficiency of transactions - write operations that modify the state of the blockchain. Solana achieves this by using a unique proof-of-history (PoH) consensus algorithm, which allows it to process thousands of transactions per second. Its core design principles are performance, scalability, and reliability.
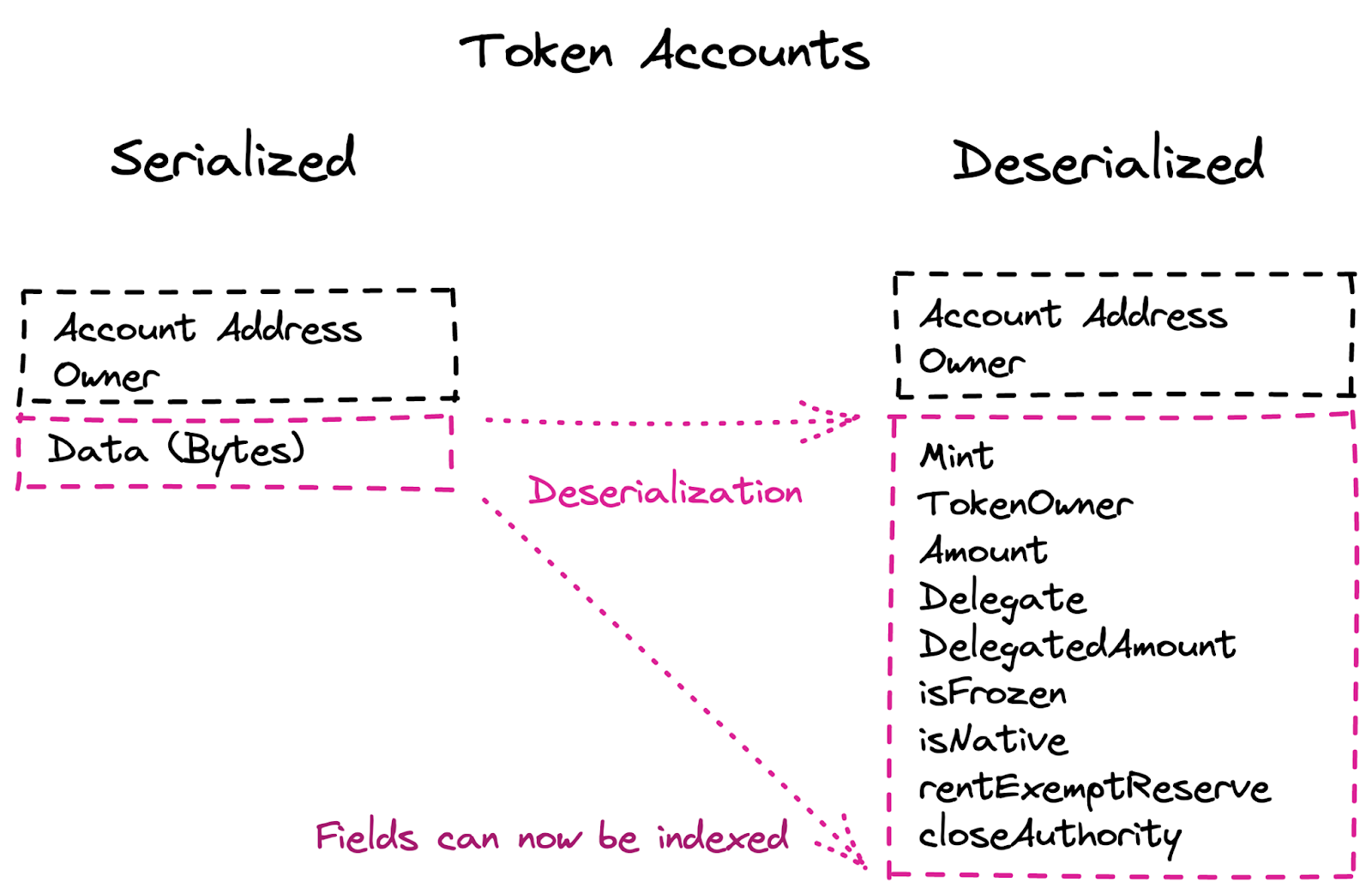
Solana’s account model is fairly simple - optimized for fast reads by account and owner addresses. Most information for each account is stored in a data field as a serialized byte array:

This storage makes it difficult to query for any data contained by each account since the data is serialized and unindexed!
So if we’d like to execute a query for all tokens a user owns, we’d need to query getProgramAccounts for the Token Program, filtering down for tokens owned by the user’s wallet address. This sounds convenient, but the underlying database does not index the Token owner field, because it is in the serialized byte array data field. This means we must scan over all accounts owned by the token program, an O(n) scan! And N is in the hundreds of millions in this case.
Many other common Solana use cases rely on this call pattern:
Enumerate all NFTs in a collection
Get all listings on Magic Eden for a specific user
Find the rarest NFT in a user’s wallet
There’s room for optimization here - accounts should be indexed in a way specific to the schemas of the serialized data they contain. Solana’s RocksDB does not do this for efficiency/abstraction - it’s reminiscent of how blocks are laid out on disc in a typical file system.
Custom Indexing of Solana data
So we’re now at the point in our web3 dApp when we want to bootstrap a backend database that will store and index data in a deserialized format. This database will allow our application to quickly find the data we want for our front end. Going back to our need to fetch all tokens that a user has staked, we’ll now have a new endpoint:
GET /app/user_wallet/:wallet_address/staked
Which will hit our database w/ a query similar to
SELECT token_amount
FROM app_stakes
WHERE wallet = :wallet_address
Since we’ve indexed the wallet column of the app_stakes table, the lookup becomes O(1)! We no longer need to wait for our target RPC provider to iterate through all token accounts to find our user’s stake!
Other Self-Indexing Motivations
There are other reasons we may want to index on-chain data ourselves:
Denormalization
A common pattern in database design is denormalization - increasing redundancy of our stored data to avoid joins and provide faster, specialized reads for various use cases. On Solana - certain entities we’re interested in tracking may have multiple accounts that constitute a single entity.
Let’s take an NFT for example - NFTs on Solana are constituted by a MintAccount, TokenAccount, a Metadata account, and additional off-chain data.

Fetching all of this data via RPC in a front end would be arduous. Indexing all accounts in our DB as separate tables means reads are still not as efficient as possible, since we require joins. Denormalizing this info into a single “NFT” table makes reads faster and more efficient.
Denormalization
Indexing data ourselves allows us to support custom aggregations. Both OLTP (like Postgres, and Cockroach) and OLAP (like Pinot) databases could be great options here to allow fast reads for aggregations, like the token-staker leaderboard:
SELECT wallet, SUM(*) as stakedTokens
FROM app_stakes
GROUP BY wallet
ORDER BY stakedTokens
LIMIT 10
Indexing via RPC
A common practice in the Solana ecosystem to maintain a database reflecting on-chain data is by utilizing RPC nodes to backfill the entities we’re interested in, then process transactions for those entities to pick up new mutations as they come in.
Solana RPC nodes come with a Subscription WebSocket API which consumers can subscribe for updates to various updates.
We can use the slotSubscribe web socket to get updated when the network has produced new blocks, then getBlock to retrieve all transactions in the block for that slot, filter down to the transactions for accounts we’re interested in, then fetch all recent account data for the accounts that we’ve observed to have changed.

This method works reasonably well and is extensible to new transaction types and new account types we may see.
However, there can be some drawbacks if we’re interested in knowing the up-to-date state of accounts on-chain...
RPC Performance
The same performance issues we were having in our dApp with RPC calls like getProgramAccounts are still happening - we’ve just moved our RPC call site from the frontend to our backend. We’ve unlocked efficient reads for our users, but all data must travel over the wire, and we’re bound to the same RPC interface on the indexing path as we were calling before.
Backfills still require getProgramAccounts, and account updates must be fetched.
Imagine streaming 100 GB of data in HTTP calls that return 100kb at a time - this is what’s happening when fetching (and backfilling) account data from RPC
In addition, RPC nodes generally serve multiple functions beyond read traffic. Many RPC nodes submit client transactions to the network and participate in consensus. These supplemental responsibilities slow down RPC nodes and stop them from excelling at serving read traffic, and can end up falling behind the network.
Pagination
RPC nodes don’t support pagination on most endpoints. This means that APIs have limited scalability as the underlying data size grows, making endpoints slower to load and more resource intensive.
Enter Geyser
This is where Geyser - a validator plugin for data streaming - comes in. We’ll discuss Geyser details, the motivations behind integrating it into your stack, and some popular plugins in the next post.

